
Running and Building ARM Docker Containers on x86
This section explains how to build an application on an x86_64 platform and run it on an NVIDIA® Jetson™ with ARM architecture.
The main benefits of cross-compilation for NVIDIA® Jetson™ are:
Speeding up application development: For example, building an application on NVIDIA® Jetson™ Nano can be very slow. Using ARM emulation will allow us to build the application on a fast x86 host and launch it on the NVIDIA® Jetson™ Nano.
Compiling is very resource-intensive. Platforms such as NVIDIA® Jetson™ Nano are limited in memory and disk space; they may not have the resources to build large and complicated packages with AI features.
Setting Up ARM Emulation on x86 #
We’ll be using QEMU and Docker to set up our emulated environment. QEMU is an open-source machine emulator and virtualizer. It allows users to build ARM CUDA binaries on their x86 machine without needing a cross-compiler.
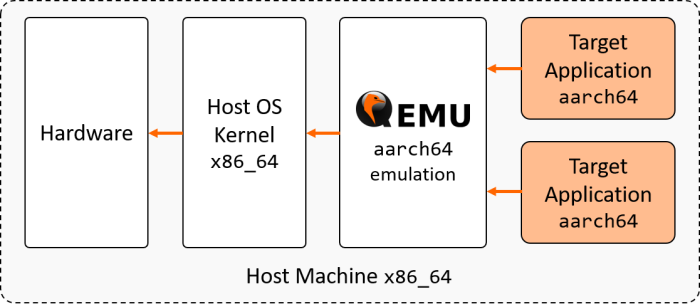
First, let’s see what happens before setting up the emulation when trying to execute a program compiled for a different architecture :
uname -m # Display the host architecture
#x86_64
docker run --platform=linux/arm64/v8 --rm -t arm64v8/ubuntu uname -m # Run an executable made for aarch64 on x86_64
# exec /usr/bin/uname: exec format error
As expected the instructions are not recognized since the packages are not installed yet. Installing the following packages should allow you to enable support for aarch64 containers on your x86 workstation:
sudo apt-get install qemu binfmt-support qemu-user-static # Install the qemu packages
docker run --rm --privileged multiarch/qemu-user-static --reset -p yes # This step will execute the registering scripts
docker run --platform=linux/arm64/v8 --rm -t arm64v8/ubuntu uname -m # Testing the emulation environment
#aarch64
The installation was successful, the emulation is working. At this point, we can now run aarch64 programs on the host x86_64 workstation. However, it is not yet possible to build and run CUDA-accelerated applications with QEMU. To add this feature, we will need to use a Linux for Tegra (L4T) base image from NVIDIA® DockerHub (see next section for additional details).
📌 Note: For advanced details on using QEMU and Docker, please refer to this repository on GitHub.
Building NVIDIA® Jetson™ Container on your x86 Workstation #
Now that QEMU is installed, we can build an application with CUDA and ZED SDK by specifying the correct parent image for our container application.
For example, to build a Docker image for NVIDIA® Jetson™ with CUDA, the following base image can be used:
FROM nvidia/l4t-base:r32.2.1
To build a Docker image for NVIDIA® Jetson™ with CUDA and ZED SDK, you can use the following base image:
FROM stereolabs/zed:3.0-devel-jetson-jp4.2
For a detailed example of how to build your own image, see Creating your Docker Image.
Deploying your Image to NVIDIA® Jetson #
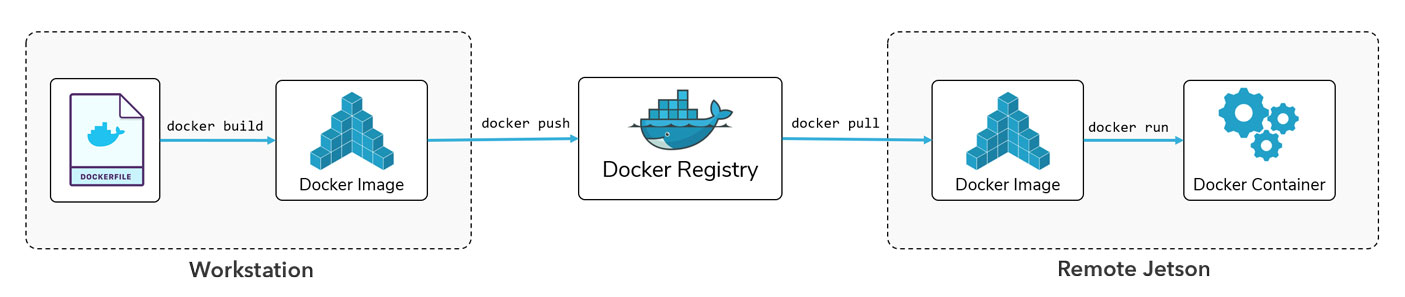
We recommend the above workflow for building and deploying your applications with Docker on NVIDIA® Jetson™. In this workflow, your source code and Dockerfiles are present on your local device (host machine). The image is built from the Dockerfile on the host and is pushed on a Docker registry that makes it accessible from a remote device (target machine). On the target machine, the Docker image is pulled from the registry and is run in a Docker container.
Build a Docker Image on the Host #
To build a Docker image on the host machine you will need to:
- Write a Dockerfile for your application (see Creating your Image section).
- Run the
docker buildcommand.
Run a Docker Image on the Target #
Pull your image from DockerHub on the target machine, and use the following command to run it in a Docker container:
docker pull {user}/{custom_image}:{custom_tag}
docker run --privileged --runtime nvidia --rm {user}/{custom_image}:{custom_tag}
📌 Note: If the image has not been pulled previously,
docker runwill pull it from the registry.